
Amazon Q Business がスキャンされたPDFのインデックス化をサポートしました

こんにちは、森田です。
以下のアップデートで Amazon Q Business がスキャンされたPDFのインデックス化をサポートしました。
さきにまとめ
以前までは、スキャンされたPDFをインデックス化したい場合は、事前に Amazon Textract 等を使って OCRを行い、テキストファイルに変換する必要がありました。
今回のアップデートによって、スキャンされたPDFであっても追加作業なしでデータソース同期を行うだけでインデックス化できるようになります。
ちなみに現在(2024/07/14)時点は、Kendraでは同様の機能は提供されていません。
やってみた
実際に、スキャンされたPDFで問題なくインデックス化できるかを試してみます。
PDFファイルの準備
今回は手書きの文字が含まれた以下のようなPDFを利用します。

PDFファイルについては、S3バケットへ配置します。
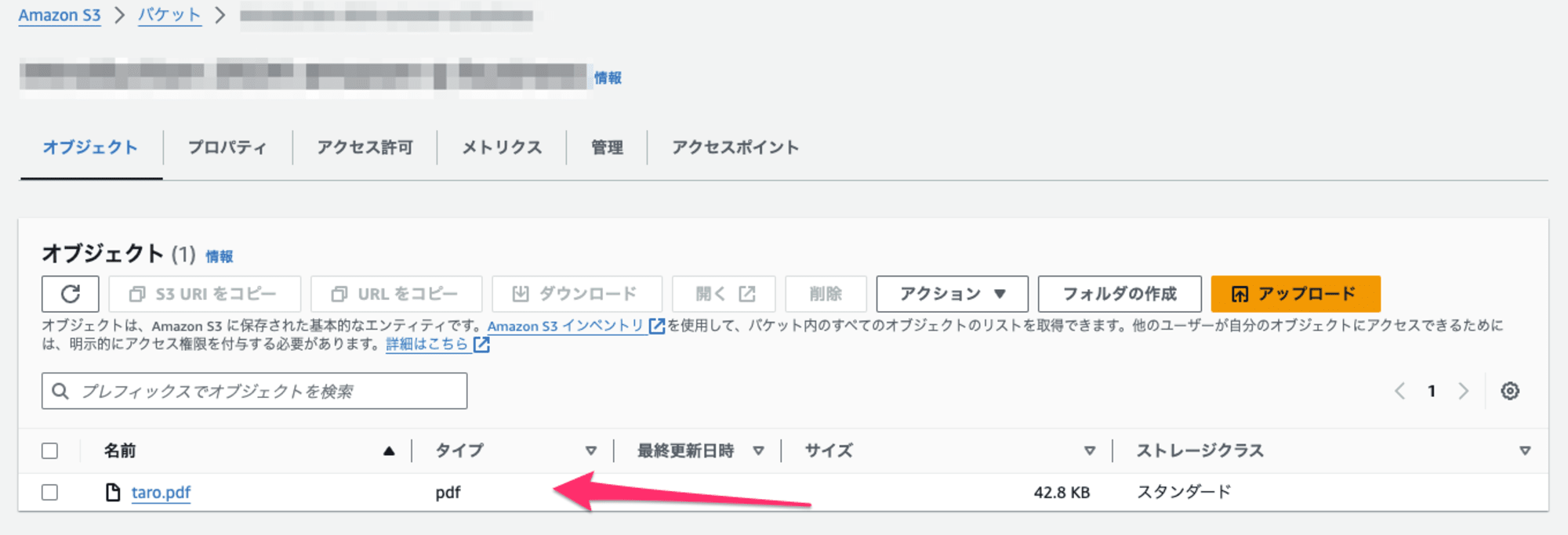
ちなみに、このファイルをKendraで読み込みを行うと同期に失敗します。
{
"DocumentId": "s3://バケット名/taro.pdf",
"IndexName": "pdf-test-index",
"IndexID": "4101d720-da9d-4f03-ac95-2664f931087b",
"SourceURI": "https://バケット名/taro.pdf",
"IndexingStatus": "DocumentFailedToIndex",
"ErrorMessage": "Document cannot be indexed since it contains no text to index and search on. Document must contain some text",
"ErrorCode": "400"
}
Amazon Q Business アプリケーションの作成
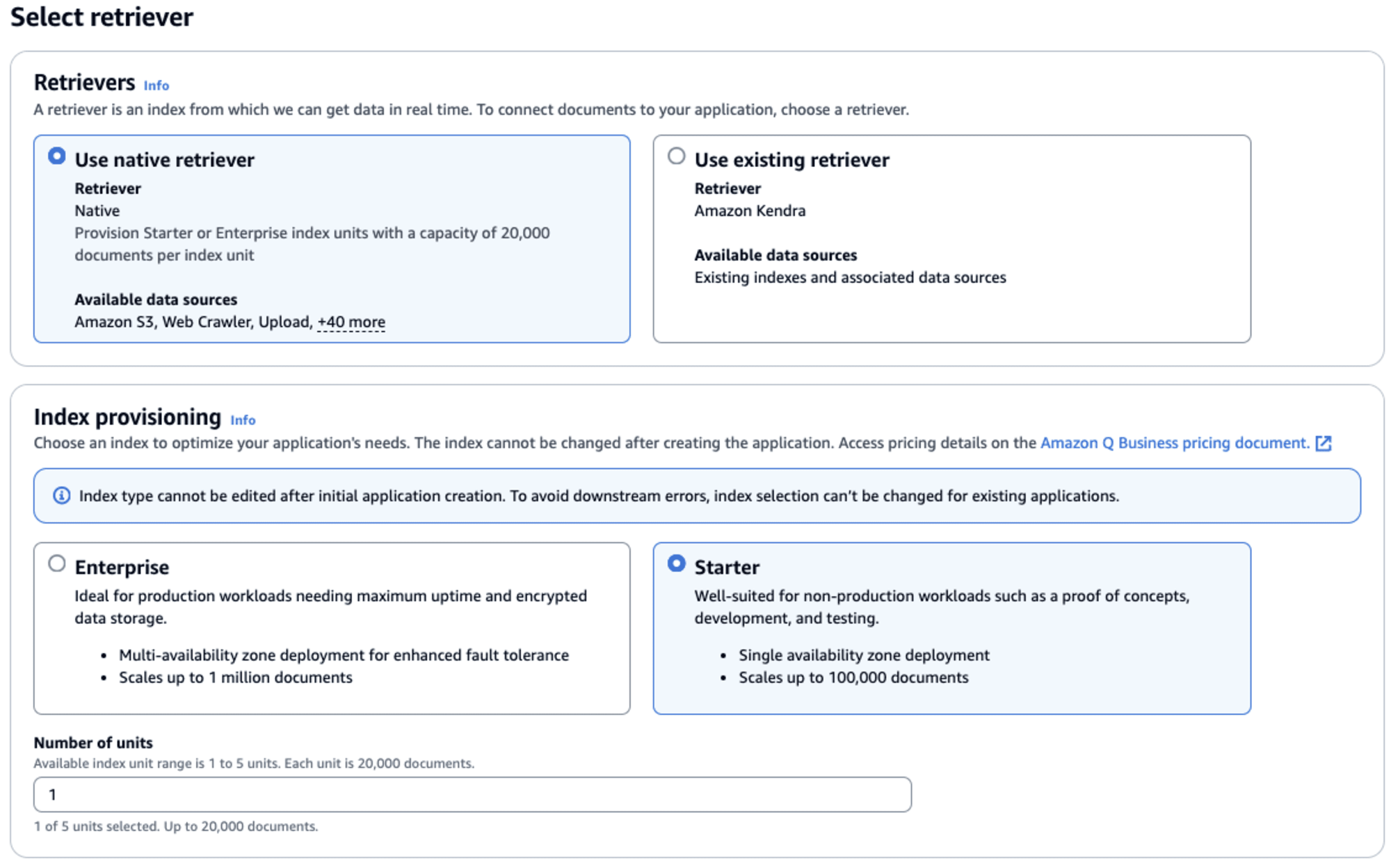
AWSコンソール上から Amazon Q Business アプリケーションの作成を行います。
基本的にデフォルト値のまま進めて問題ありませんが、Retrieverについては、 native retriever を選択するようにします。
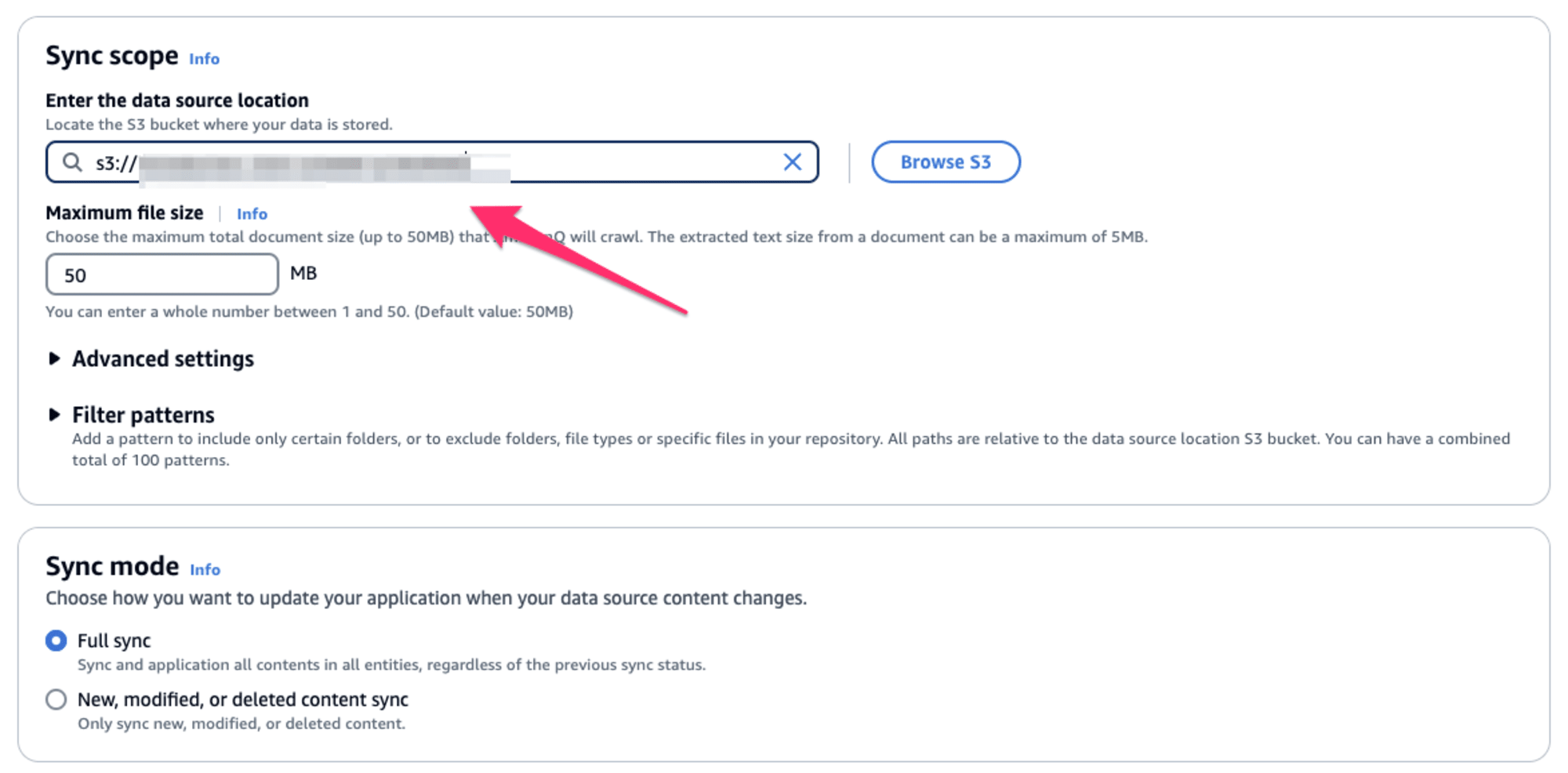
データソースについては、Amazon S3を選択し、PDFの配置されたS3バケットのパスを入力します。
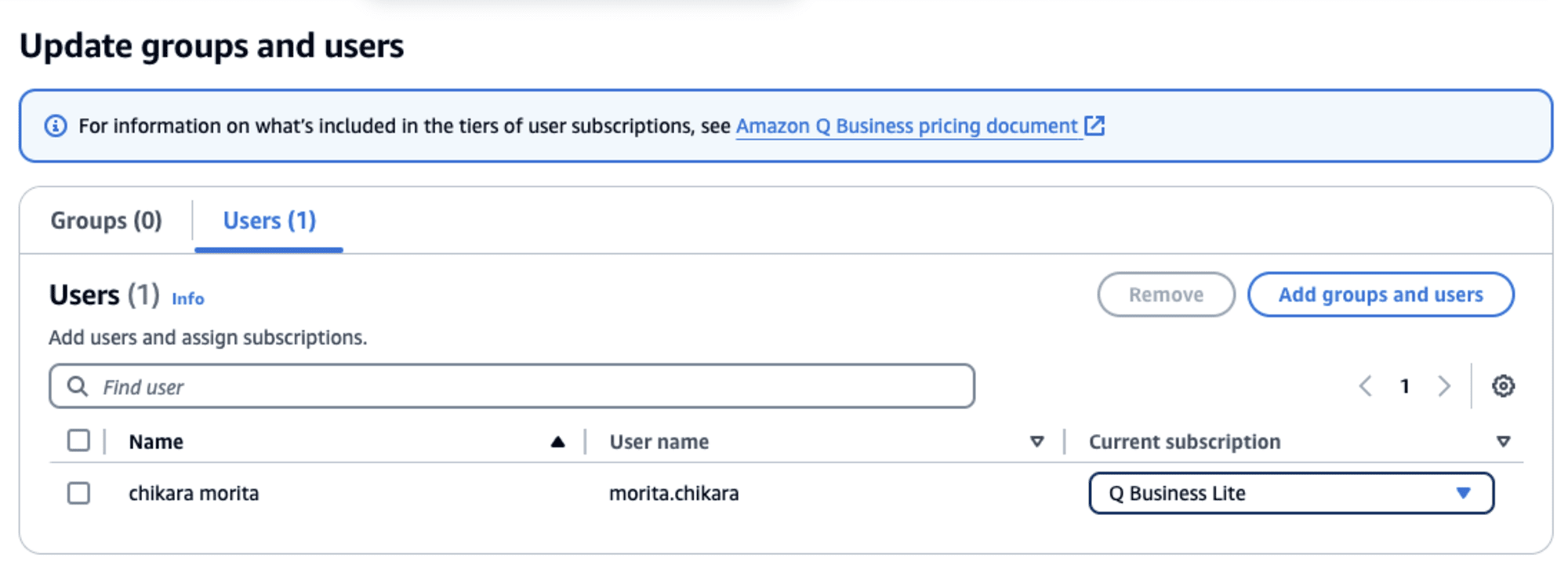
最後にWEBアプリケーションから動作確認を行うため、ユーザの追加を行い、アプリケーションの作成を完了させます。
データソースの同期
では、S3バケットのデータソースの同期を行います。
同期については、しばらく待つ必要があります。
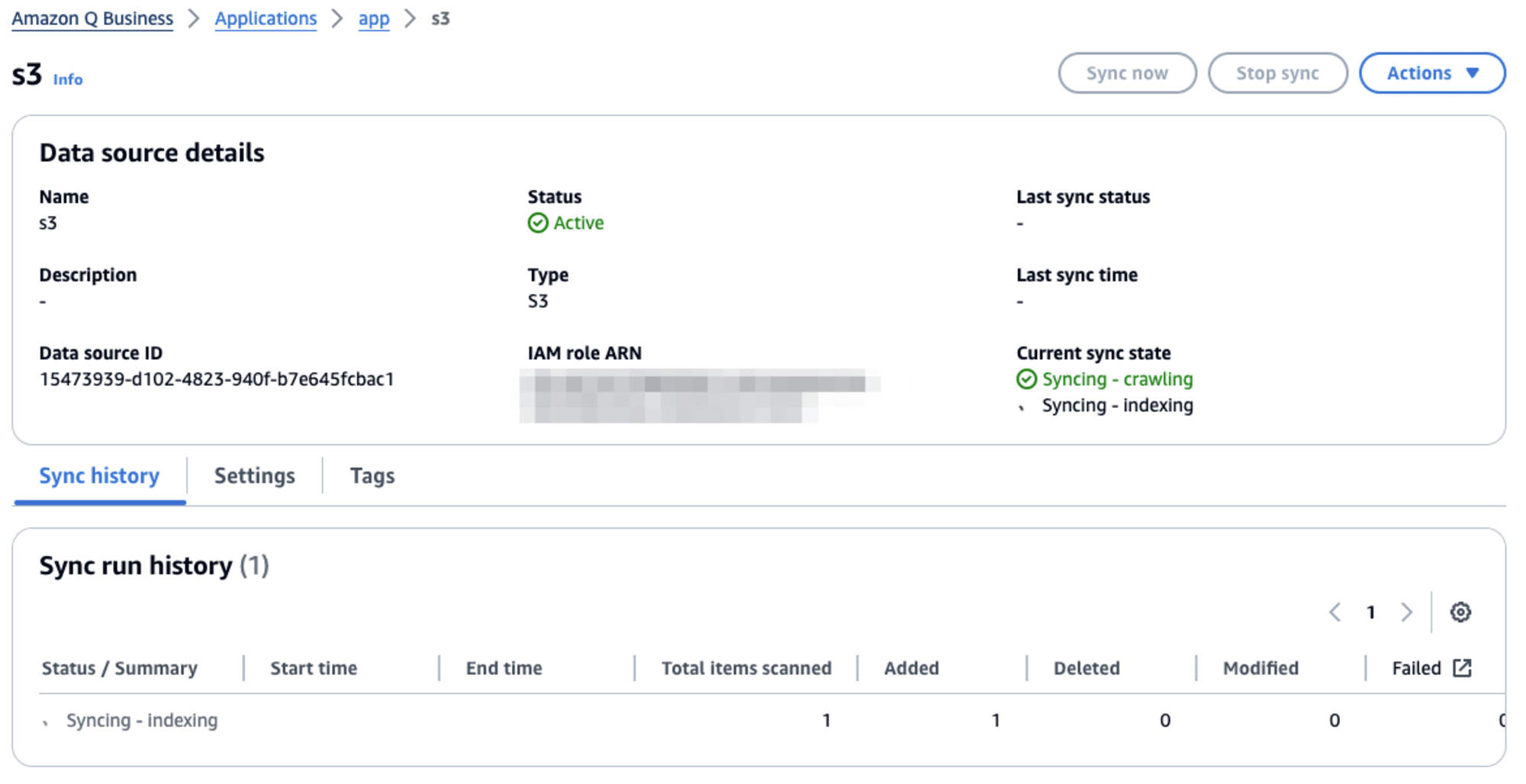
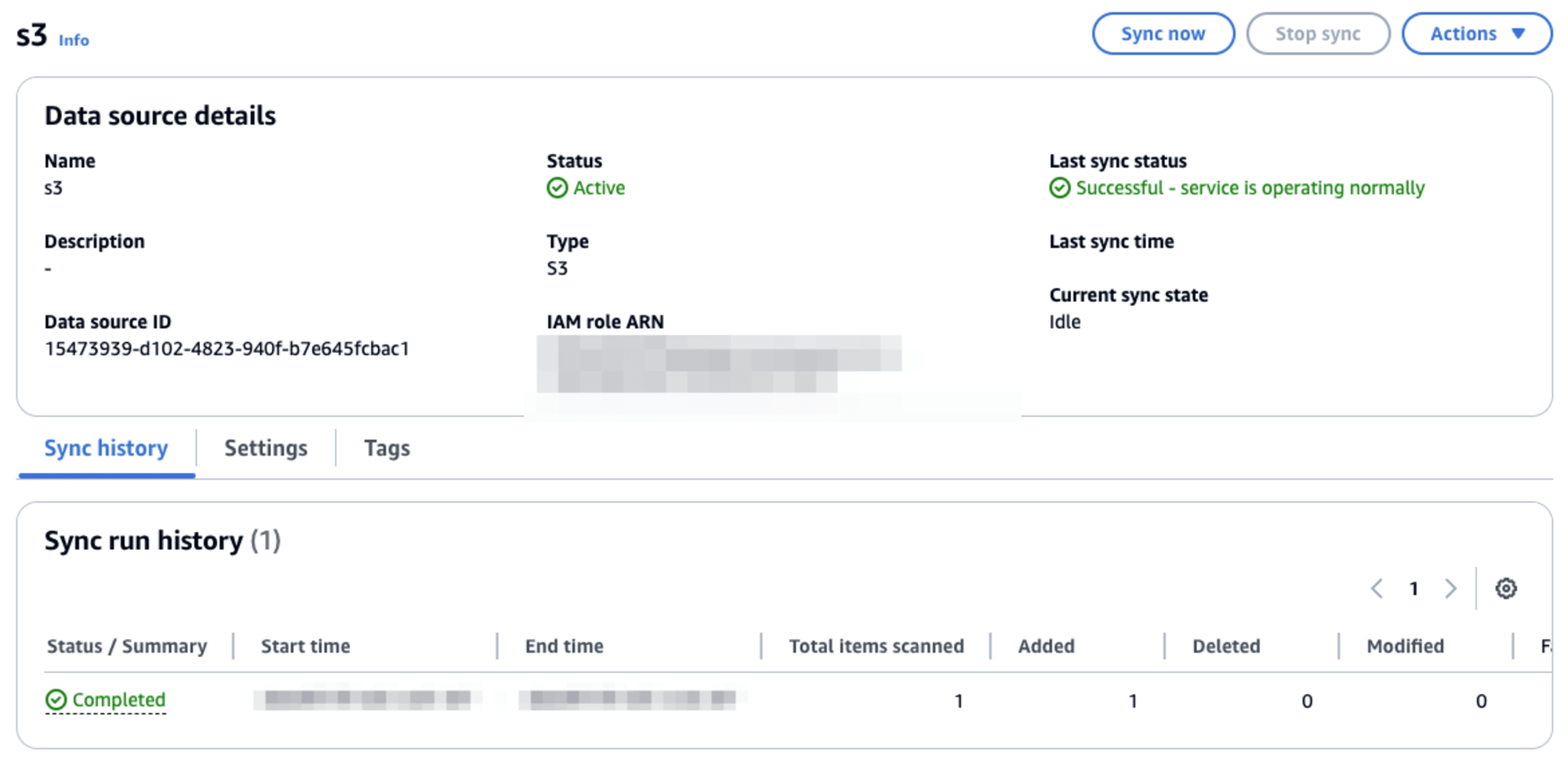
しばらく待つと、 Status が以下のように Completed となりました。
WEBアプリケーションからの確認
では、正常にインデックスに追加されたかをWEBアプリケーションから質問することによって確認してみます。
アプリケーションから以下の質問文を送信します。
Tell me what you know about Taro.
(太郎について知っていることを教えてください。)
すると、以下のようにPDFの内容を使って回答をしてくれました。
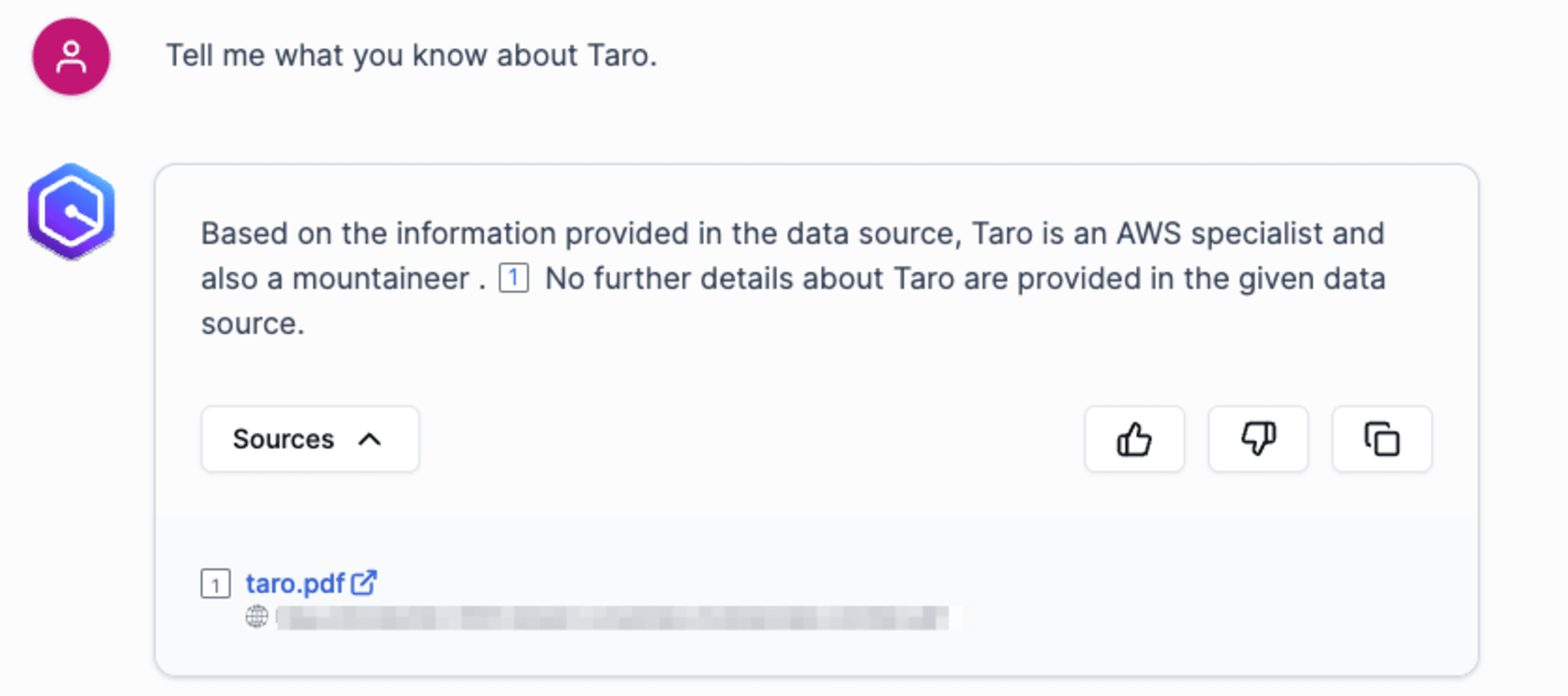
Based on the information provided in the data source, Taro is an AWS specialist and also a mountaineer.
No further details about Taro are provided in the given data source.
上記の結果からも問題なくインデックス化できていそうですね。
さいごに
スキャンされたPDFをサポートしたため、今まではインデックス化を諦めていたドキュメントでも、もしかすると利用できる可能性があります。
また、現在は、スキャンされたPDFは、Amazon Q Business のみでのサポートですが、今後Kendraでもサポートしてくれることを期待しています。

![[レポート]Amazon Redshiftで生成AIのためのデータ戦略を構築 #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg)


![[REPORT] Building an AWS solutions architect agentic app with Amazon Bedrock #DEV331 #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/53SNOsU11M3m4DqvPA0xlI/6c4e2658f47b8521afbac66d1cb1c792/eng-reinvent-2024-sessionreport.jpg)
